Application of learning-based autofocus in 4D Digital Subtraction Angiography, incorporating implicit neural models for advance encoding of motion and 4D blood flow information.
[2024] Motion Compensation for 4D Digital Subtraction Angiography via Deep Autofocus and Implicit Neural Motion Models
Huang H, Lu A, Gonzales F, Ehtiati T, Siewerdsen JH, Sisniega A. Motion Compensation for 4D Digital Subtraction Angiography via Deep Autofocus and Implicit Neural Motion Models. 8th International Conference on Image Formation in X-Ray Computed Tomography. 2024; Bamberg, Germany.
Presentation Slides
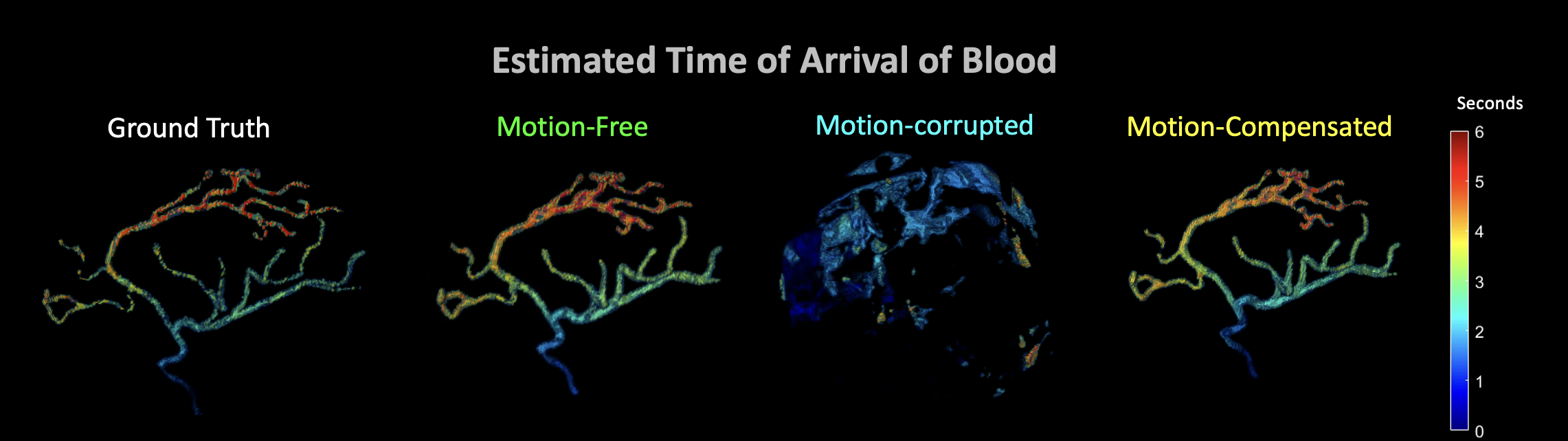
4D-DSA offers time-resolved 3D information of contrast concentration in vascular structures and has seen increased use in the neuro-interventional suite. Most current approaches to 4D-DSA are implemented using interventional cone-beam CT systems and involve the acquisition of a non-contrast-enhanced reference mask and a contrast-enhanced volume during contrast administration. The final 4D-DSA dataset is obtained under assumptions of perfect stationarity of the patient during both CBCT scans. However, cone-beam CT often shows moderately long acquisition time, making it susceptible to motion artifacts that could significantly degrade the accuracy of 4D-DSA. Recent developments in motion compensation with image-based autofocus, integrating learning-based autofocus metrics and implicit neural representation of the motion trajectory, has demonstrated reliable and robust performance in solving complex motion in CBCT images. In this work, we propose a novel framework that incorporates motion compensation into the 4D-DSA pipeline. 4D-DSA is obtained via a multi-stage approach involving deep autofocus motion estimation acting on the non-contrast-enhanced mask, simultaneous motion estimation and registration of the contrast-enhanced volume, and estimation of the time-dependent volumetric contrast distribution.
Extending The Concept of Learning-Based Autofocus Metric to Deformable Motion in Interventional CBCT by Utilizing Context-Aware Architecture
[2024] Deformable Motion Compensation in Interventional Cone-Beam CT with a Context-Aware Learned Autofocus Metric
Huang H, Liu Y, Siewerdsen JH, et al. Deformable motion compensation in interventional cone-beam CT with a context-aware learned autofocus metric. Med Phys. 2024; 51: 4158–4180.
Interventional Cone-Beam CT (CBCT) offers 3D visualization of soft-tissue and vascular anatomy, enabling 3D guidance of abdominal interventions. However, its long acquisition time makes CBCT susceptible to patient motion. Image-based autofocus offers a suitable platform for compensation of deformable motion in CBCT, but it relies on handcrafted motion metrics based on first-order image properties and that lack awareness of the underlying anatomy. This work proposes a data-driven approach to motion quantification via a learned, context-aware, deformable metric, $\mathbf{VIF_{DL}}$, that quantifies the amount of motion degradation as well as the realism of the structural anatomical content in the image.

Using Neural Network as Autofocus Metric in Rigid Motion Compensation
[2022] Reference-free learning-based similarity metric for motion compensation in cone-beam CT
H. Huang, J.H. Siewerdsen, W. Zbijewski, C. R. Weiss, M. Unberath, T. Ehtiati, A. Sisniega, “Reference-free learning-based similarity metric for motion compensation in cone-beam CT,” in Physics in Medicine & Biology.
Purpose. Patient motion artifacts present a prevalent challenge to image quality in interventional cone-beam CT (CBCT). We propose a novel reference-free similarity metric (DL-VIF) that leverages the capability of deep convolutional neural networks (CNN) to learn features associated with motion artifacts within realistic anatomical features. DL-VIF aims to address shortcomings of conventional metrics of motion-induced image quality degradation that favor characteristics associated with motion-free images, such as sharpness or piecewise constancy, but lack any awareness of the underlying anatomy, potentially promoting images depicting unrealistic image content. DL-VIF was integrated in an autofocus motion compensation framework to test its performance for motion estimation in interventional CBCT.
Methods. DL-VIF is a reference-free surrogate for the previously reported visual image fidelity (VIF) metric, computed against a motion-free reference, generated using a CNN trained using simulated motion-corrupted and motion-free CBCT data. Relatively shallow (2-ResBlock) and deep (3-Resblock) CNN architectures were trained and tested to assess sensitivity to motion artifacts and generalizability to unseen anatomy and motion patterns. DL-VIF was integrated into an autofocus framework for rigid motion compensation in head/brain CBCT and assessed in simulation and cadaver studies in comparison to a conventional gradient entropy metric.
Results. The 2-ResBlock architecture better reflected motion severity and extrapolated to unseen data, whereas 3-ResBlock was found more susceptible to overfitting, limiting its generalizability to unseen scenarios. DL-VIF outperformed gradient entropy in simulation studies yielding average multi-resolution structural similarity index (SSIM) improvement over uncompensated image of 0.068 and 0.034, respectively, referenced to motion-free images. DL-VIF was also more robust in motion compensation, evidenced by reduced variance in SSIM for various motion patterns (σDL-VIF = 0.008 versus σgradient entropy = 0.019). Similarly, in cadaver studies, DL-VIF demonstrated superior motion compensation compared to gradient entropy (an average SSIM improvement of 0.043 (5%) versus little improvement and even degradation in SSIM, respectively) and visually improved image quality even in severely motion-corrupted images.
Conclusion. The studies demonstrated the feasibility of building reference-free similarity metrics for quantification of motion-induced image quality degradation and distortion of anatomical structures in CBCT. DL-VIF provides a reliable surrogate for motion severity, penalizes unrealistic distortions, and presents a valuable new objective function for autofocus motion compensation in CBCT.

